易刊全自动去水印工具 使用说明
易刊去水印工具 使用说明
安装后即可使用 有任何问题 请联系作者哦~
用户快速上手指南
软件简介
这是一款去水印的桌面应用,集成了 AI 水印检测、特征提取、提示词生成与去除功能,支持批量图片处理、区域选择、自动修复和多种自定义操作。界面友好,操作简单,适合各类图片去水印需求。
1. 安装与环境配置
- 启动软件后,切换到"安装教程"标签页。
- 选择服务器模式(本机/局域网),填写服务器地址和端口(如 http://localhost:8092)。
- 点击"安装/启动"按钮,启动 LAMA 去水印服务器。
- 如需停止服务,点击"停止"按钮。
- 配置完成后,点击"保存配置"以便下次自动加载。
注意: 若服务器启动失败,请检查端口占用或以管理员身份运行。
水印检测需要使用没有量化的 Qwen/Qwen2.5-VL 模型 或 官方支持量化的 AWQ 模型
注意:在 ollama 或 lvstudio 运行的 gguf 模型均不能获取准确水印坐标
如果有10GB显存 以上显卡想本地部署的 可以用 vllm 部署
经测试 vllm 中部署的 AWQ 系列模型最可靠
有什么不懂的或出什么问题可以问deepseek或GPT
window 系统可以用 docker 部署示例
保存为 docker-compose.yml 修改模型位置 C:\models
version: '3.8' services: vllm: image: vllm/vllm-openai:latest ports: - "8000:8000" volumes: - C:\models:/models - ${USERPROFILE}/.cache:/root/.cache ipc: host deploy: resources: reservations: devices: - driver: nvidia capabilities: [gpu] command: > --model /models/Qwen2.5-VL-7B-Instruct-AWQ --served-model-name Qwen/Qwen2.5-VL-7B-Instruct-AWQ --trust-remote-code --tensor-parallel-size=1 --quantization awq --dtype float16 --gpu-memory-utilization 0.7 --max-model-len 4096 --block-size 16 --swap-space 4 --max-num-batched-tokens 4096 --max-num-seqs 1 environment: - CUDA_VISIBLE_DEVICES=0 - HF_ENDPOINT=https://hf-mirror.com - CUDA_LAUNCH_BLOCKING=1
安装 docker deskstop 后在命令行中运行
docker-compose up -d
下载模型示例:
set HF_ENDPOINT=https://hf-mirror.com huggingface-cli download Qwen/Qwen2.5-VL-7B-Instruct-AWQ --local-dir C:/models/Qwen2.5-VL-7B-Instruct-AWQ
在 ubuntu 系统运行速度最快,以下是安装示例:
# 下载最新版本的 Miniconda 安装脚本 wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh chmod +x Miniconda3-latest-Linux-x86_64.sh # 安装 Miniconda # ./Miniconda3-latest-Linux-x86_64.sh -b -p $HOME/miniconda3 ./Miniconda3-latest-Linux-x86_64.sh -u # 重新加载 shell 配置以使 conda 命令可用 source ~/.bashrc conda --version # 配置 conda 使用国内镜像源(例如清华镜像) conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/ conda config --set show_channel_urls yes conda create -n py311 python=3.11 -y # 激活 conda 环境 conda activate py311 # 安装 Jupyter Notebook conda install -c conda-forge jupyterlab -y # 安装 cuda toolkit 10.2 conda install cudatoolkit=10.2 -y # 安装 PyTorch 和 torchvision pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu118 # vllm pip install vllm
安装后运行示例:
conda activate py311 vllm serve /media/jacky/新加卷/models/Qwen2.5-VL-7B-Instruct-AWQ \ --served-model-name Qwen/Qwen2.5-VL-3B-Instruct-AWQ \ --trust-remote-code \ --quantization awq \ --dtype float16 \ --max-model-len 4096 \ --gpu-memory-utilization 0.7 \ --tensor-parallel-size 1 \ --max-num-batched-tokens 2048 \ --swap-space 4 \ --block-size 16 \ --max-num-seqs 2
2. 批量导入图片
方式一:文件夹导入
- 在主界面或"水印选择"面板,点击"选择文件夹"按钮。
- 选择包含图片的文件夹,支持 PNG/JPG/JPEG/BMP/TIFF 等格式。
- 软件会自动批量导入所有图片,支持千张级别批量处理。
方式二:手动选择
- 点击"打开图像"按钮,手动多选图片文件。
- 支持重复导入,已存在的图片会自动去重。
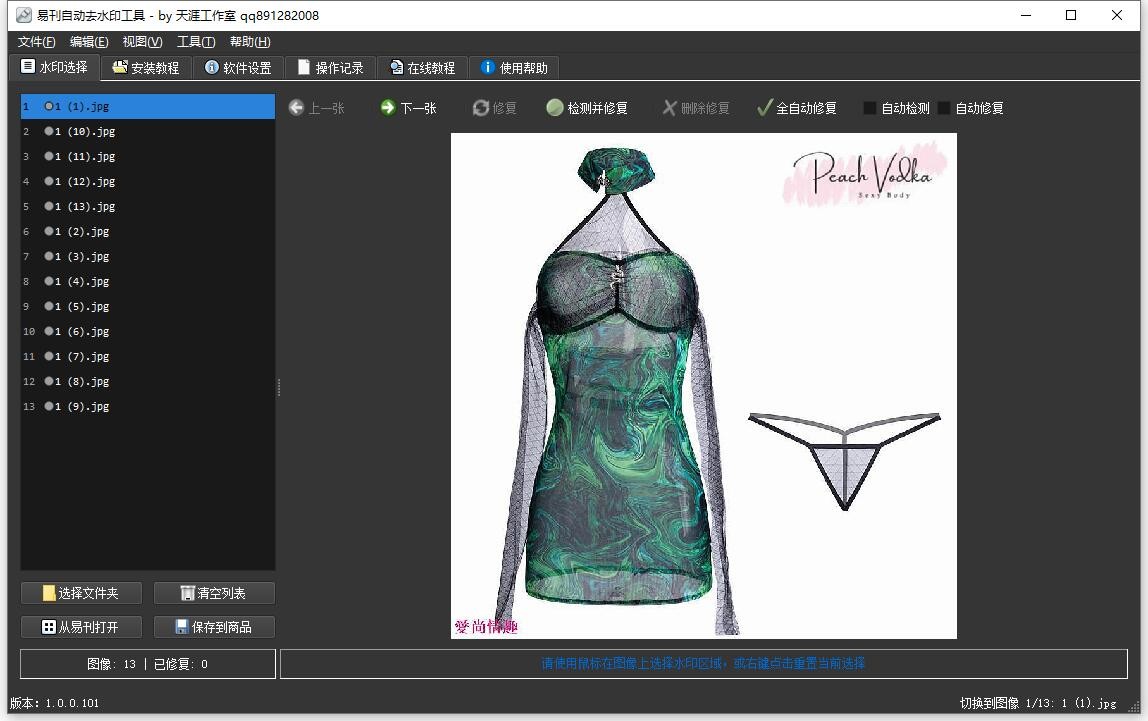
3. 图片浏览与区域选择
- 导入图片后,左侧显示图片列表,点击可切换浏览。
- 右侧显示图片预览,使用鼠标拖动可选择水印区域。
- 区域选择完成后,状态栏会提示选区位置和大小(需大于5x5像素且在图片内)。
- 可多次调整选区,支持撤销和重置。
4. 水印特征分析与提示词生成
- 选定图片和区域后,点击"分析水印特征"按钮。
- 软件会自动提取水印特征,结果显示在"水印特征描述"区域。
- 点击"生成提示词"按钮,自动生成适合去水印的提示词。
- 可在"水印特征提取提示词"区域自定义提示词,并点击"保存提示词"。
- 若需恢复默认提示词,点击"恢复默认"按钮。
5. 测试提示词效果
- 点击"测试提示词"按钮,软件会用当前提示词检测水印区域。
- 检测结果会以红框高亮显示在图片上,并弹窗显示区域坐标和大小。
- 若未检测到水印,软件会给出提示,可尝试调整选区或提示词。
6. AI 去水印与自动修复
单张去水印
- 选择图片和区域后,点击工具栏"修复"按钮(或按 Delete 键)。
- 软件会调用 AI 修复服务器,自动去除选中区域水印。
- 修复结果自动保存到 fixed 子文件夹,并在界面中高亮显示。
自动检测与修复
- 勾选"自动检测"后,切换图片时会自动检测水印区域。
- 勾选"自动修复"后,选择区域后会自动执行去水印。
- 点击"检测并修复"按钮,可一键自动检测并修复当前图片。
- 点击"全自动修复"按钮,可批量自动检测并修复所有图片。
7. 撤销与批量管理
- 点击"删除修复"按钮(Ctrl+Z),可撤销当前图片的修复结果。
- 支持批量删除所有修复图、清空图片列表。
- 支持图片浏览、上一张/下一张切换、修复状态统计。
8. 常见问题与注意事项
- 服务器无法连接/修复失败:请检查服务器地址、端口配置,确保服务器已启动。
- 图片无法加载:请确认图片格式受支持,路径无误。
- 选区无效:选区需大于5x5像素且在图片范围内。
- 修复效果不理想:可多次调整选区或自定义提示词,反复测试。
- 批量处理慢:大批量图片建议分批导入,避免卡顿。
9. 高级功能
- 支持从易刊商品数据库导入/保存图片(需配置数据库)。
- 支持自定义修复参数、特征模板、批量自动化处理。
- 支持操作记录、日志追踪、参数备份与恢复。
10. 联系与反馈
如有更多问题或建议,请联系开发者或在项目主页提交 issue。
天涯工作室 QQ:891282008 网址:http://www.tenyasoft.com
祝您使用愉快!

一键安装后默认使用CPU,可自行安装英伟达 nvidia cuda GPU加速,加速前处理一张图片需要6~10秒,加速后 1~3秒即可,请查看使用说明,下载 并安装
torch-2.1.0+cu118-cp38-cp38-win_amd64.whl
torchvision-0.16.0+cu118-cp38-cp38-win_amd64.whl
百度网盘 链接: https://pan.baidu.com/s/1FY2kP1TjIp_A89okkRJRBQ?pwd=cdcq 提取码: cdcq
- 发表于 2024-11-13 11:23
- 阅读 ( 3799 )
- 分类:默认分类
10 篇文章
作家榜 »
-
 lovesbaby
10 文章
lovesbaby
10 文章
-
 Nereiram
0 文章
Nereiram
0 文章
-
 Annelcaf
0 文章
Annelcaf
0 文章
-
 JaslyPaF
0 文章
JaslyPaF
0 文章
-
 Martinreuch
0 文章
Martinreuch
0 文章
-
 Maikan1acits
0 文章
Maikan1acits
0 文章
-
 JamesMep
0 文章
JamesMep
0 文章
-
 RonaldHalty
0 文章
RonaldHalty
0 文章
